Abstract
We present an approach to understanding how to create a consulting business for a personal service, in this case hair beauty. The approach uses experimentation, in the form of systematically varied ideas (Mind Genomics.) The strategyis to expose respondents to combinations of services, identify which particular ideas in the combination ‘drive’ positive reactions, and then focus on those ideas in communication. Rather than asking respondents, Mind Genomics works with combinations, presented rapidly, forcing the response to be intuitive, rather than considered. Mind Genomics reveals new-to-the-world groups of consumers, mind-sets, who respond to different messages in communications, and identifies individuals with these mind-sets through a PVI, personal viewpoint identifier.
Introduction
The business of beauty, ‘hope in a bottle’ as some have called it, continues to grow. The desire to be beautiful to others, seemingly built-in to our condition as human beings, continues to drive business growth as the economies of the world improve, these economies moving into the 21st century, and expanding beyond subsistence to better living, and even to living at the ‘high end,’. The rise of wealthy multi-national companies, specializing in the creation of personal ‘beauty’ in all forms, for all parts of the body, attests to ineradicable desire of people to look attractive.
Macro-economic studies of the growth of the beauty industry can go just so far, and no further. The expertise of marketing and market researchers, replete with their knowledge about the industry, the solution providers (e.g., salons, products) and the customers, provide a lot of information and indeed with the Internet a torrential, ever-increasing amount each day. Whether one reads the newspapers, listens in on social media, or works in salons and stores, one cannot escape the world of beauty, massive, dynamic, growing. The industry reports, the stock market, the newspaper and other sources of ads and promotions attest to the dynamism.
What then about the individual, however? We mean here the consumer who buys the beauty product or service. What can we learn about them, information beyond the conventional information of ‘who they are’, and ‘why they buy?’ We don’t mean the standard information available from trend studies, from so-called Big Data, or even from focus groups convened to learn how to sell a product or service. Rather, we mean here the mind of the individual, when dealing with a product in the world of beauty.
Sadly, in the world of science there is relatively little research devoted to the way people make ordinary decisions. There are, of course, studies of entire categories and verticals, but these studies tend to be cross-sectional, in the spirit of a macro-economic analysis, such as what are people in general thinking, what are people, in general, buying, and so forth. The science which emerges from these studies tends to be strongly driven by theory, by mathematical models, and replete with generalities about human behavior gleaned from the analysis. In contrast, there is very little science of ‘every day’ experience. We know that people experience daily life, and make decisions, one decision after another. But what can we learn about the structure of these decisions? Can we create a science of daily life, almost a science of the mind as the mind or the person confronts the very ordinary, quotidian situations, which make up day to day living?
There are, of course, academic studies, although far fewer than one might guess, especially in the world of beauty. Studies of beauty as they pertain to daily life tend not to be the topic of science, although when one searches hard enough, there are many papers, most about beauty in the culture rather than beauty and specifically hair as a topic of science, from the person’s point of view [1–5]. There is, of course, a literature on beauty from the point of view of science, although this information tends to be clinical, even though it deals with an emotionally important topic [6,7] The real and often riveting information about one’s experience with beauty, decision-making, and actions comes from the popular press, from news articles, and stories to interest lay readers, who find utterly fascinating these stories about beauty and its many facets [8–12].
Mind Genomics as an organizing principle
In the world of products, services, and marketing, professionals are realizing that it is increasingly impossible to make judgments about business tactics without the necessary evidence. In previous decades the beauty business as well as the perfume business were dominated by peoples who we would call ‘business titans’ when running a large corporation, or superb professionals when designing products, especially perfumes. The cosmetic industry was spared some of the cult of personality because it had to deal with product functionality as well as product image. Nonetheless, the cult of personality left a legacy of relatively little knowledge about the mind of the customer. Compared to the world of food, the world of cosmetics and beauty is lacking in depth knowledge of customers, and is still heir to some of the forces of charismatic personalities.
Author Moskowitz has developed a new approach to understanding the consumer, not so much based on conventional research such as focus groups, surveys, or tracking studies, as based on the world-view of experimental psychology. The approach is morphing into an emerging science called Mind Genomics, which is executed as a survey but in fact is an experiment to probe the mind of the customer[13–16].
A good analogy for Mind Genomics, elaborated below, is ‘the MRI of the mind.’ The intellectual history of Mind Genomics can be traced to the pioneering work of psychologists and statisticians [17], as expanded by Green and his associates at the Wharton School of Business, The University of Pennsylvania [18,19].
The fundamentals of Mind Genomics are simple, elaborated in the four steps below:
- EXPERIMENT: Approach the topic as an experiment, present test ideas (message) in combinations (vignettes), acquire ratings, and deconstruct the ratings to the contribution of the individual ideas. The statistics involved are subsumed under the rubric of experimental design [20].
- MIND-SETS: Identify different mind-sets, defined as arrays of ideas which focus on different aspects of the topic. The statistics involved are subsumed under the rubric of clustering, which places people or other objects into non-overlapping groups, based upon the pattern of features [21,22].
- ASSIGNMENT OF NEW PEOPLE TO MIND-SETS: Assign new people to a specific mind-set, based upon a short test. The approach is an algorithm developed by author Gere, and called the PVI, the personal viewpoint identifier
- SEND THE ‘RIGHT MESSAGE’ TO THE ‘RIGHT PERSON’ AT THE ‘RIGHT TIME.’ Present each person with the appropriate messages, defined as those messages which appeal to the mind-set [23].
Doing the Mind Genomics study
During the past 15 years the Mind Genomics protocol for research has become increasingly standardized in terms of the research choreography. The standardization enables the researcher to set up the study quickly, in a matter of hours, executed the study, and have results back in a matter of three-four hours, with the data analyzed. The rapid design, implementation, and analysis, has occurred because the Mind Genomics process has been ‘templated’. We present the research template here, a template that has been followed for many dozens of studies.
- Define the topic. For this study the topic is ‘what is important in one’s choice of a beauty hair consultant from the point of view of an ordinary individual?’ For the best results, the scope of the topic should be limited to a specific and well-defined topic, a topic which can be expressed in a single sentence. Most researchers need practice in order to define the topic in a succinct, operationally meaningful way, a way whose description can produce a word picture in the mind of an individual not familiar with the topic.
- Define a set of questions which tell a story. These questions (or silos) are never shown directly to the respondents in the Mind Genomics study. Rather, the questions are used to elicit answers (elements), these answers in turn shown to respondents in various combinations, as described below. It is worth noting that the most difficult part of the Mind Genomics study comes in this second step. Many researchers have a very hard time thinking in this structured, story-telling fashion. The discipline required to ask the series of related questions comes with practice, and in some ways the Mind Genomics process ‘re-wires’ the mind of the respondent. Table 1 presents the four questions, and the four answers for each question.
- Combine these answers into short, easy to read combinations, so that the respondent can quickly read and evaluate. Figure 1 (left panel) shows an example of a vignette as the respondent will see it, with the view being the smartphone. The same vignette can be configured for a tablet or a personal computer, as shown in Figure 1 (right panel.)
Table 1. The raw material for the Mind Genomics study, comprising four questions which ‘tell a story’ and four answers to each question. HBC = Hair Beauty Consultant
|
Question 1 –What does the HBC do? |
|
|
A1 |
often works with hair which is falling out |
|
A2 |
works with overly oily hair |
|
A3 |
gives real professional advice |
|
A4 |
works with people who are not able solve their hair problem |
|
Question 2 – Why would you want THIS particular HBC |
|
|
B1 |
hair consultant is known by friends |
|
B2 |
hair consultant writes for social media |
|
B3 |
beauty salons often recommend |
|
B4 |
hair consultant gives courses for new hair professionals |
|
Question 3 –What does the HBC deliver? |
|
|
C1 |
thorough discussion after examination |
|
C2 |
present alternative best 2 or 3 solutions |
|
C3 |
present products and/or treatments for the client |
|
C4 |
present products for the clients |
|
Question 4 –How do the client and HBC interact |
|
|
D1 |
client has long term relationship … personal project |
|
D2 |
client has project and monthly visits |
|
D3 |
client gets reduced salon prices as part of treatment |
|
D4 |
weekly meetings on computer to SEE and DISCUSS progress |
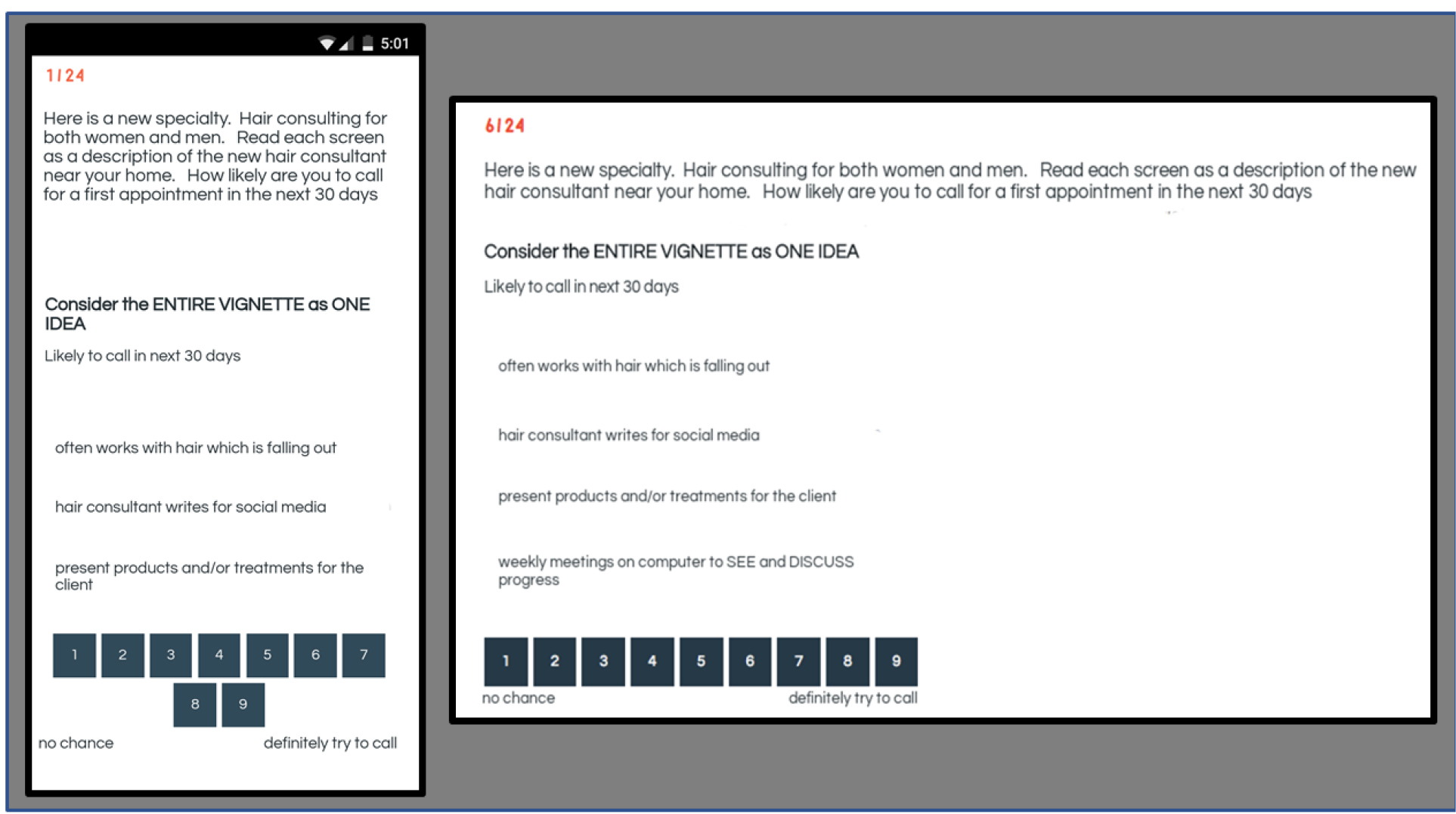
Figure 1. Examples of a vignette, as it appears on the screen of a smartphone (left), and the same vignette as it appears on the screen of a tablet or personal computer (right)
The vignette shown in Figure 1 contains no connectives. Rather, the elements are placed on the page, left-justified, one element following another, the elements on separate lins Often, those who will use the research findings feel that it is impossible for the consumer respondent to rate the combination because the elements seem to have been thrown together haphazardly. Most of the experience of researchers working in the evaluation of combinations of ideas has been focused on getting the stimulus, the vignette, ‘just right,’ connectives and all, with the vignette appearing as a paragraph. That paragraph format, so rational and acceptable to many, becomes, in fact, quite onerous to read after the respondent has read and rated 3–4 of these paragraphs.
Mind Genomics works within a different world view, focusing on presenting messages as they are presented in the real world, unconnected, almost ‘thrown’ at the respondent. It is the job of the respondent to make a judgment as in real life. The structure is difficult to discern, so that in the end, most of the respondents simply ‘give up,’ and assign ratings according to their intuition, System 1 in the words of Nobel Laureate Daniel Kahneman [24].
Despite the apparent randomness of the combinations, nothing could be further from the truth. The reality is that the vignettes, the test combinations, are crafted through an underlying experimental design which prescribes the precise set of 24 combinations to make, so that each element appears equally often, all 16 elements appear in a statistically independent fashion, each vignette comprises 2–4 elements and at most one answer from each question (i.e, at most one element from each silo). A permutation scheme ensures that each respondent evaluates different combinations. That is, the combinations tested by one respondent are different from the combinations tested by any other respondent. The permutation scheme is discussed by Gofman&Moskowitz [25], based upon a patent [26].
Table 2 presents data from the first eight vignettes from a respondent, along with the preparation of the design and data for analysis by OLS (ordinary least-squares) regression. The respondent’s ID number is 7. The Mind Genomics system does not record WHO the respondent IS, but records the date of birth and the gender. Thus, it is possible to use age and gender as stratifying variables. The respondent in this study was also asked about the concern with their hair. Two of the four responses were either not concerned or only mildly concerned with their hair. Respondents choosing one of these two answers were put into the group stating that there was little or no concern. The remaining respondents chose answers reflecting modest or strong concern, and were put into the second group, who are concerned with their hair.
Table 2. Experimental design underlying the vignettes
|
Panelist |
7 |
|||||||
|
Gender |
Female |
|||||||
|
Age |
65 |
|||||||
|
Hair Conc |
Yes |
|||||||
|
Mind Set# |
3 |
|||||||
|
Vig1 |
Vig2 |
Vig3 |
Vig4 |
Vig5 |
Vig6 |
Vig7 |
Vig8 |
|
|
Design |
||||||||
|
Question A |
3 |
4 |
4 |
4 |
2 |
0 |
1 |
3 |
|
Question B |
0 |
2 |
3 |
4 |
2 |
2 |
3 |
4 |
|
Question C |
3 |
4 |
1 |
2 |
0 |
0 |
2 |
1 |
|
Question D |
2 |
4 |
2 |
0 |
3 |
1 |
1 |
1 |
|
Binary Recode |
||||||||
|
A1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
|
A2 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
A3 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
A4 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
B1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
B2 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
|
B3 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
|
B4 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
|
C1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
|
C2 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
|
C3 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
C4 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
D1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
|
D2 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
D3 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
D4 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Response Data |
||||||||
|
Rating |
7 |
6 |
6 |
6 |
6 |
5 |
7 |
6 |
|
Top 3 (6–9 → 100; rest → 0) |
100 |
0 |
0 |
0 |
0 |
0 |
100 |
0 |
|
Bot 3 (1–3 → 100; rest → 0) |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Response Time (Seconds) |
5.4 |
7.2 |
9 |
6.2 |
3.9 |
6.8 |
8.6 |
5.9 |
The basic information we have about the respondent is that she is a 65-year-old female who states that she is concerned with her hair. Furthermore, as we will see later in the paper, the respondent falls into Mind-Set #3, based upon the pattern of her responses. The assignment of respondents to one of a set of complementary, mutually-exclusive and exhaustive mind-sets for this particular topic of hair care consulting provides yet a fourth way to define WHO the respondent is, this time based upon how the respondent thinks about hair beauty consultants.
Below the respondent specifications are listed the identification code for the test elements which appeared in vignettes 1–8, respectively. Each vignette has at most one element from each silo, or one answer from each question, but in reality there are vignettes entirely lackingan answer to one question (e.g., vignette 1 lacks an answer to Question B), and vignettes entirely lacking an answer to two questions (e.g., vignette 6 lacks an answer to both Question A and Question C, respectively.) Respondents have no problem evaluating vignettes which are incomplete, since respondents ‘graze’ for information, rather than slavishly read the vignette word by word.
As the experimental design is laid out, most computer programs have a difficult time analyzing the data. The experimental design is not intrinsically numeric, but rather descriptive. It is important to transform the data to a form that the statistics program can use. One very straightforward way to prepare the data for analysis recodes the experimental design to 0’s (when an element is absent from a vignette), or 1’s (when an element is present.)
Table 2 further shows the recoding of the design from four rows to 16 rows. Each row corresponds to one of the 16 elements. There are 16 rows, labelled A1 to D4, to represent each of the 16 answers or elements in a vignette. Each column, in turn, corresponds to one of the eight vignettes. The cells show the coding of a specific vignette and a specific element. When the cell has a ‘1’, the vignette contains that element. When the cell has a ‘0,’ the vignette lacks that element. Looking down at the composition of one vignette, we see at most four ‘1’s and the rest ‘0’s, which tells the computer program and the researcher that the vignette has no more than four elements, and tells the program which specific four (or three or two) elements are present in the vignette.
Below the binary recording are the response data, comprising the actual rating (1–9), the binary transform for positive responses (7–9 → 100, 1–6 → 0), the binary transform for negative responses (1–3 → 100; 4–9 → 0), and the response time in sections. The binary transform is used in the spirit of consumer research, which continues to present data to the end-user as binary, NO vs YES. The specific division of the 9-point scale into the two asymmetric halves, 1–6 versus 7–9 was done following the standard research protocol used in Mind Genomics studies since the late 1980’s, 30+ years ago.
The arrangement of the data in the form shown in Table 2 allows the computer program to process the data in a numeric form, creating a ‘model’ or equation. The model or equation shows how the presence/absence of the elements in a vignette ‘drive’ the response. The creation of these models, the interpretation of their meaning, and the application of the results to practical issues will be the topic of the rest of this paper.
Results
How do individual respondents rate the vignettes?
Each respondent rated 24 different vignettes. We have two transformation or recodings of the same data, a positive recoding for liking, and a negative recoding for disliking. The transformation of the vignettes tells us whether, for the particular vignette the respondent ‘likes’ the vignette (positive recoding: ratings 7–9 → 100), whether the respondent dislikes the vignette (negative recoding: ratings 1–3 → 100) or whether respondent is indifferent (neither like nor dislike).
The average transformed rating for each respondent shows the proportions of positive versus negative average responses. A respondent who liked every one of the 24 vignettes would have a value of 100 across the 24 vignettes for the transformation of ‘like’. That respondent would have all 0’s for the recoding for dislike. Thus the average of the positive recodes for an individual tells us the degree to which the individual ‘likes’ everything. The average of the negative recodes for the same individual tells us the degree to which the individual ‘dislike’ everything.
When we plot the average likes (abscissa, X axis) versus the average dislikes (ordinate, Y axis), with one point for each respondent,
Figure 2 shows us that most of the respondents cluster either at the bottom of the graph (like most of the vignettes, dislike none or a few), or cluster at the left side of the graph (*dislike most of the vignettes, like none or a few). Respondents are polarized. They either like or dislike what they read. There are only a few respondents who show indifferent responses. These would be in the middle of the graph.
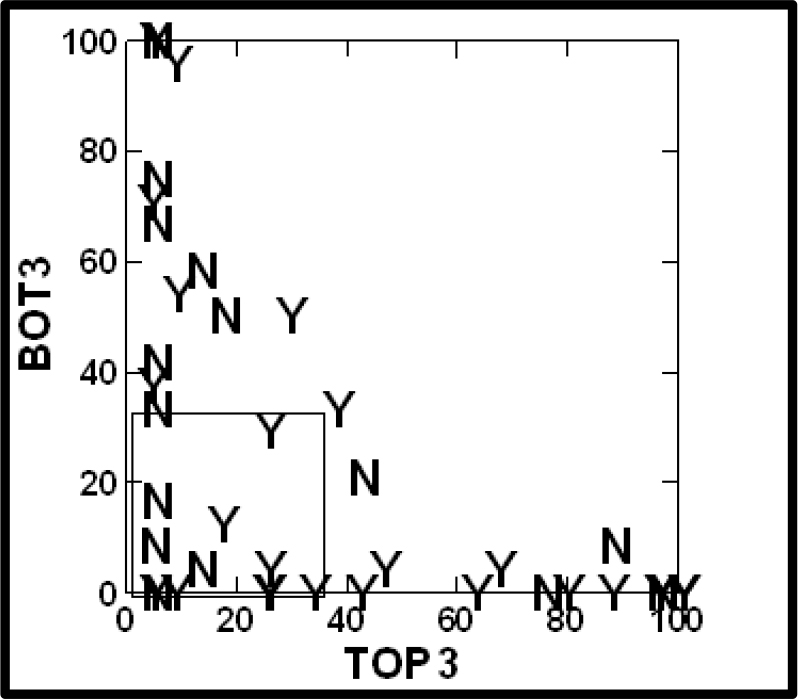
Figure 2. Scatterplot, showing the distribution of positive and negative averages regarding the rating of the 24 vignettes, after the binary transform. Each letter corresponds to a respondent. Y = respondent says concerned with hair; N = respondent says not concerned with hair.
When we classify the respondents by their self-stated concern with hair, we can represent them by N (not interested) or Y (interested). Figure 2 suggests that those who say that they are concerned with their hair tend to be more positive, on average, and those who say that they are not concerned with their hair tend to be more negative, both with respect to rating the vignettes.
Creating a model by OLS, ordinary least-square regression
The essence of Mind Genomics is to understand the specific ‘drivers’ of responses, which in our case becomes the specific messages driving a respondent to say: ‘I am interested in a beauty consultant.’ The rating scale conveys that interest, doing so for the different vignettes that were created. The notion of exposing respondents to different combinations comes from the world of human experience, where the most typical situation confronting a person is a set of features or items in an environment, and the reaction of the person to that combination. It is often impossible for a person to identify the particular features of the combination confronting the person responsible for the subsequent action taken by the person.
When the researcher combines the different elements or messages into a combination using experimental, the above-mentioned vignette, the issue identifying the ‘driving’ element is made simpler. Various statistical techniques falling into the general statistical system called ‘regression’ relate the independent variables, those features driving the response, to the dependent variable, the nature of the response itself. There is simply a need to ensure that the predictor variables of interest are ‘statistically independent,’ and not strongly linked with each other. Regression disentangles the response to the mixture into the contributions of the components of the mixtures, in our cases the messages
We use OLS (ordinary least-squares) regression to relate the presence/absence of the 16 elements to the rating, in our case defined as the 0/100 after binary transformation. Table 2 showed us the way the data are formatted. We know the combination, and we measure the response. For then regression analysis whose results are shown in Table 3, we combined the data from all respondents who are members of the class, ‘class’ or ‘group’ defined as total, as gender, as age, or as self-defined concern with one’s hair.
Table 3. Performance of the elements by total panel and key self-defined subgroups
|
Coefficients of the model relating the presence/absence of elements to ‘Interested’ (Top2 (4 and 5 on 5-point scale of interested)) |
Total |
Male |
Female |
Age 18–29x |
Age 30–49x |
Age 50+x |
Concern YES |
Concern NO |
|
|
Base size |
|||||||||
|
Additive constant |
25 |
21 |
28 |
-19 |
25 |
50 |
17 |
39 |
|
|
B2 |
hair consultant writes for social media |
6 |
10 |
2 |
15 |
4 |
5 |
0 |
16 |
|
B4 |
hair consultant gives courses for new hair professionals |
3 |
4 |
1 |
6 |
-1 |
8 |
-2 |
10 |
|
D1 |
client has long term relationship … personal project |
3 |
0 |
7 |
12 |
1 |
1 |
3 |
3 |
|
A2 |
works with overly oily hair |
2 |
-3 |
8 |
5 |
-2 |
9 |
6 |
-4 |
|
D4 |
weekly meetings on computer to SEE and DISCUSS progress |
1 |
-5 |
7 |
12 |
-1 |
-2 |
1 |
-1 |
|
D2 |
client has project and monthly visits |
1 |
0 |
2 |
9 |
2 |
-3 |
3 |
-3 |
|
C2 |
present alternative best 2 or 3 solutions |
0 |
3 |
-3 |
22 |
-3 |
-2 |
-3 |
6 |
|
C3 |
present products and/or treatments for the client |
0 |
4 |
-4 |
13 |
-5 |
2 |
-3 |
5 |
|
B1 |
hair consultant is known by friends |
0 |
-1 |
2 |
7 |
-4 |
3 |
-3 |
4 |
|
A1 |
often works with hair which is falling out |
0 |
-3 |
3 |
2 |
-1 |
1 |
5 |
-6 |
|
C1 |
thorough discussion after examination |
-1 |
-2 |
-1 |
22 |
-5 |
-5 |
1 |
-3 |
|
B3 |
beauty salons often recommend |
-2 |
-1 |
-2 |
11 |
-4 |
-3 |
-5 |
3 |
|
C4 |
present products for the clients |
-2 |
0 |
-5 |
13 |
-6 |
-4 |
-4 |
2 |
|
D3 |
client gets reduced salon prices as part of treatment |
-2 |
-3 |
1 |
9 |
-4 |
0 |
-2 |
-1 |
|
A3 |
gives real professional advice |
-3 |
-4 |
-2 |
6 |
-5 |
-4 |
-2 |
-4 |
|
A4 |
works with people who are not able solve their hair problem |
-3 |
-5 |
0 |
7 |
-7 |
-1 |
-1 |
-6 |
Table 3 shows the key information emerging from the regression analyses. We interpret the data in the following way:
- The additive constant. This value is the estimated percent of responses to the vignette that would be 100 (viz., originally 4–5) in the absence of elements. The reader will at once realize that all vignettes comprised as many as four elements, as few as two elements, and never one or no elements, respectively. Thus, the additive constant is a baseline value, purely an estimated parameter.
- The additive constant can be interpreted as a baseline of acceptance, when we look at the binary transformed data. It is the estimated percent of responses that would be 4–5 on a 5-point scale in the absence of elements. When our goal is to achieve a high total score, beginning with a high additive constant means that the basic feeling towards the product or the service is strong, and the element do not have to do much work. With a low additive constant, the opposite is the case, and the elements must do ‘all the work.’ The additive constant need not be a positive number. The mathematics behind the additive constant and the individual element-linked coefficients, regression analysis, does not set limits on the additive constant
- The additive constants range dramatically, from a high of 50 for respondents ages 50+ (older respondents are basically interested in a hair consultant), to a low of -19, virtually 0 for respondents ages 18–29 (younger respondents are basically uninterested in a hair consultant.)
- Surprisingly, those who say that they are concerned about their hair are less interested in the hair beauty consultant (additive constant = 17), versus those who say that they not concerned about their hair (additive constant = 39).
- The data suggest that it will be the elements which make the difference.
- To make reading the data easier, we have shaded all elements which achieve a coefficient of 8 or higher in any subgroup. Studies using Mind Genomics suggest that the statistical value significance is around 8 or so, using the principles of inferential statistics. Observations by author Moskowitz using these data in many studies further suggest that when the coefficient is 8 or higher, the element performs well in other applications, such as advertising.
- The total panel shows no elements which drive interest. Although this finding may be disconcerting to many, since research is presumed to show opportunities, the reality is that most of the messages studied by Mind Genomics simply do not persuade, do not drive people to try the product, use the service. Even though a message may have been used for years does not make the message by definition ‘sacred,’ and an accepted part of one’s marketing and sales portfolio.
- Dividing respondents by ender shows similar additive constants, but only one strong element, that element appealing to males: B2 – hair consultant writes for social media
- Dividing respondents by age shows an exceptional number of messages appealing to the younger respondent, age 18–29
present alternative best 2 or 3 solutions
thorough discussion after examination
hair consultant writes for social media
present products and/or treatments for the client
present products for the clients
client has long term relationship … personal project
weekly meetings on computer to SEE and DISCUSS progress
beauty salons often recommend
client has project and monthly visits
client gets reduced salon prices as part of treatment
The older respondents (age 50+) show only two very strong elements
works with overly oily hair
hair consultant gives courses for new hair professionals
Those who say that they are not concerned with their hair
hair consultant writes for social media
hair consultant gives courses for new hair professionals
Difference mind-sets searching for hair care
The premise of Mind Genomics is that in any topic area where human decisions are made on the basis of exterior information, there exist different groups of ideas which ‘travel together.’ These ideas are called mind-sets. They are embodied in an individual who is said to ‘hold’ a specific mind-set, but they are not the individual. They are cohesive sets of ideas. We only discover these ideas, however, through experimentation. We need people to help us reveal these mind-sets.
The mind-sets are discovered by a simple statistical method called ‘clustering,’ which puts together different things (e.g. ideas) based upon the similarity of their patterns. Clustering does not necessarily reveal fundamental, basic ideas, although it may. Rather, clustering is a heuristic, designed to create smaller, non-overlapping groups from a large, perhaps inchoate group of items a group without seeming commonalities.
Clustering comes in many variations. With each variation of the clustering method emerges a different set of clusters, or in our case, mind-sets. The fact that there is not a perfect set of fundamental groups should not be a cause for upset. All clustering attempts to do is to find approximately different groups, so that these groups can be treated in a more appropriate way for themselves. Rather than assuming all people to be identical in what they want, or to assume that each person is totally unique, making personalization almost unachievable, clustering finds approximations to different grounds, which can be then studied separately to see the messages to which they respond.
Mind-set segmentation in Mind Genomics enjoys the benefit of segmenting a population on the basis of the precise words that will be used to send them offers. That is, instead of segmenting or clustering the population on the basis of some factors which clearly divide them, and then looking for the messages appropriate for each segment, Mind Genomics segments the people on the messages that are relevant to the topic. The segmentation is more crystallized by Mind Genomics because the segments are created on precisely the topic which is being explored.
The mechanics of clustering for these data follow the now-standard process for Mind Genomics studies. We begin by computing a ‘distance’ between every pair of respondents, that distance computed by a simple formula: D = (1 – Pearson Correlation). The Pearson Correlation coefficient tells us the degree of linear relation between two variables. When two variables are perfectly related to each other in a positive sense, the Pearson Correlation is +1 so the variable D becomes 0. This makes intuitive sense. The two variables behave identically. When two variables are perfectly correlated, but moving in opposite directions, the Pearson Correlation is –1, so the variable D becomes 2.
The clustering algorithm works with these distances, to put the different respondents into either two or three non-overlapping clusters or mind-sets. The process attempts to make the set of distances D values, have as great a value for the distances between clusters or mind-sets, and at the same time have a small value for the distances between members within a cluster.
Table 4 shows the coefficients for the total panel, for the two complementary Mind-Sets when we extract two clusters, and the three complementary Mind-Sets when we extract three clusters. We do not know which group of Mind-Sets to choose. Thus far, the process has been strictly mathematical, working with the values of the abovementioned variable ‘D’ or distance between upon the Pearson Correlation.
Table 4. Performance of the elements by total panel, two emergent mind-sets and three emergent mind-sets.
|
|
|
Total |
Mind-Set 2A |
Mind-Set 2B |
Mind-Set 3C |
Mind-Set 3D |
Mind-Set 3E |
|
|
Additive constant |
25 |
15 |
35 |
27 |
33 |
15 |
|
Mind-Set C1 – Not really interested in anything, not a prospect for a hair beauty consultant |
|||||||
|
Mind-Set C2 – Want a hair consultant who is clearly an expert, and ‘knows’ people and products |
|||||||
|
B2 |
hair consultant writes for social media |
6 |
2 |
10 |
3 |
11 |
3 |
|
C3 |
present products and/or treatments for the client |
0 |
-1 |
1 |
-5 |
7 |
-6 |
|
B4 |
hair consultant gives courses for new hair professionals |
3 |
0 |
6 |
-1 |
6 |
3 |
|
Mind-Set C3 – Want a hair beauty consult who is involved in a long-term relation with client |
|||||||
|
D1 |
client has long term relationship … personal project |
3 |
6 |
0 |
-1 |
-2 |
11 |
|
A2 |
works with overly oily hair |
2 |
6 |
-2 |
-7 |
2 |
10 |
|
D4 |
weekly meetings on computer to SEE and DISCUSS progress |
1 |
6 |
-5 |
-6 |
-4 |
10 |
|
D2 |
client has project and monthly visits |
1 |
4 |
-3 |
0 |
-2 |
6 |
|
B1 |
hair consultant is known by friends |
0 |
-1 |
1 |
-3 |
0 |
3 |
|
A1 |
often works with hair which is falling out |
0 |
5 |
-4 |
4 |
-5 |
3 |
|
D3 |
client gets reduced salon prices as part of treatment |
-2 |
0 |
-3 |
-3 |
-5 |
3 |
|
C1 |
thorough discussion after examination |
-1 |
5 |
-7 |
-2 |
-3 |
1 |
|
C2 |
present alternative best 2 or 3 solutions |
0 |
1 |
0 |
-1 |
3 |
-2 |
|
B3 |
beauty salons often recommend |
-2 |
-2 |
-2 |
-1 |
-1 |
-2 |
|
A4 |
works with people who are not able solve their hair problem |
-3 |
-1 |
-3 |
-6 |
1 |
-3 |
|
A3 |
gives real professional advice |
-3 |
-2 |
-3 |
-7 |
0 |
-3 |
|
C4 |
present products for the clients |
-2 |
0 |
-4 |
-5 |
1 |
-4 |
We employ two criteria to add judgment to the process:
- Parsimony. When clustering, the better solution should be the smaller solution, but still one that can be interpreted immediately, because it makes sense. In our study we have extracted both two and three Mind-Sets. We do not know which of these two we will select. Both are parsimonious.
- Interpretability. The clusters or Mind-Sets should ‘tell a story,’ and an obvious one. When we look at Table 4, we see that there are few strong performing elements when we extract two Mind-Sets by clustering. In contrast, when we extract three Mind-Sets, we find three interpretable groups:
Mind-Set C1 – Not really interested in anything, not a prospect for a hair beauty consultant
Mind-Set C2 – Want a hair consultant who is clearly an expert, and ‘knows’ people and products
Mind-Set C3 – Want a hair beauty consult who is involved in a long-term relation with client
Finding these respondents in the population
How one finds these Mind-Sets in the population has challenged researchers for a number of years, ever since the issue of applying the data to commercial and social uses has arisen. Decades ago, the market researcher William Wells introduced the idea of psychographic segmentation [23], suggesting that people could be divided by their minds and values. This led to lifestyle segmentation, based upon the way a person lives, and afterwards to behavioral segmentation, especially when shopping on the web. All of these segmentations work, dividing the people, but not identifying what to say for the specific situations of one’s life, the daily micro-worlds in which we live. Mind Genomics does so, but faces the same problem as all other segmentations based upon how people think.
An analysis of who the respondents are by age, gender, and interest in caring for one’s hair suggests that these Mind-Sets are spread through the population in a way that cannot be predicted easily from knowing WHO the respondent is, or CONCERN that the respondent has about her or his hair. Thus, we are left with a powerful finding about the mind of the prospective client for hair beauty consulting, yet the frustration of knowing that although these prospects exist, they cannot easily be identified. In fact, they not even know that they are prospective clients.
Author Gere has developed the PVI, the personal viewpoint identifier, which allows a respondent to answer six questions based upon the 16 answers shown in Table 1. Figure 3 shows the six questions, and the two possible answers from each question. The pattern of answers from a single is used in conjunction with the table of coefficients (Table 4). There are 64 possible patterns of responses, when the question has two possible answers. The 64 patterns are mapped to membership in one of the three Mind-Sets. Once the person has completed the PVI, in 30 seconds or faster, the person’s mind-set can be discovered, least with less guessing than before. Figure 4 shows the feedback for each mind-set. This feedback can either be given to the respondent and/or stored by the researcher/consultant for future efforts with this particular individual. The actual link to the PVI for this study as of this writing (June, 2019) can be found at: http: //162.243.165.37: 3838/TT33/

Figure 3. The PVI for the Hair Beauty Consultant
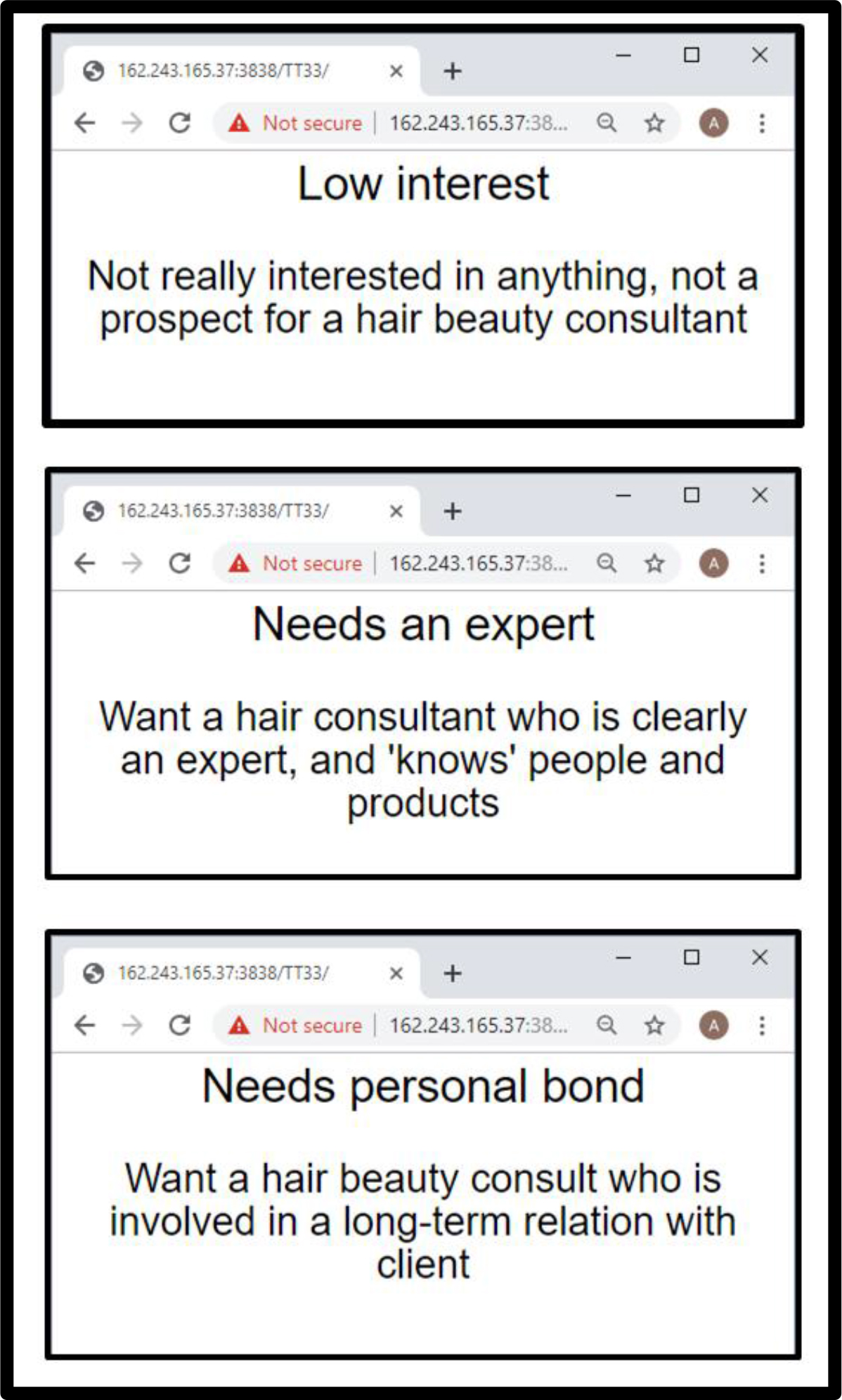
Figure 4. The feedback from the VPI. Each mind-set has its own feedback, sent either to the beauty consultant and/or the client.
Beyond what interests to what engages – Response time
The foregoing sections reveal the dramatic differences among respondents in the degree to which specific messaging appeals to them. Another dimension of important is engagement, the degree to which a specific message engages attention by being read.
The Mind Genomics system measures the response time for each vignette, doing so to the nearest tenth of a second. Since the experiment is conducted on the Web, without any supervision, occasionally (about 10% of the time) the response time is exceedingly long, last 10 seconds or longer, a time that other studies have shown to be exceptionally long. For all response times exceeding 9.0 seconds, we truncated the response time to 9.0 seconds.
Figure 5 shows the average response times across the 24 vignettes for each respondent. The respondent either one who defines herself/himself as concerned about hair (Y) or not concerned about hair (N). Our ingoing hypothesis was that those respondents who say that they are concerned about hair would spend, on average a longer time reading the vignette. We reject the hypothesis. The response times are similarly distributed, so any difference in average across all respondents would be minor at best.

Figure 5. Average response times across the 24 vignettes. Each letter corresponds to a respondent, who self-defines as either concerned about their hair (Y) or not concerned about their hair (N).
The degree to which the individual elements can engage may also be estimated using regression analysis. The ingoing experimental design is known for each respondent, as is the response time in seconds. We can create a simple model relating the presence/absence of the 16 elements to the response time. The model is written without an additive constant, under the assumption that in the absence of elements the response time would be 0 seconds. The equation is expressed asResponse Time = k1(A1) + k2(A2) … K16(D4)
Table 5 shows the coefficients for the response time models. The models were estimated from all the data relevant for the key subgroup. That is, the only data used to estimate the model for males are the data from males. Similarly, the only data used to estimate the model for Mind-Set 3E are respondents in Mind-Set 3E.
Table 5. Engagement – The estimated response times attributed to each message or element.
|
|
Total |
Male |
Female |
Age 16 to 29 |
Age 30 to 49 |
Age 50 Plus |
Concern YES |
Concern NO |
Mind-Set 3C Not Interested |
Mind-Set 3D An expert |
Mind-Set 3E Personally involved |
|
|
C2 |
present alternative best 2 or 3 solutions |
1.3 |
1.3 |
1.2 |
-0.1 |
1.5 |
1.6 |
1.5 |
0.8 |
1.0 |
1.6 |
1.2 |
|
D3 |
client gets reduced salon prices as part of treatment |
1.2 |
1.1 |
1.4 |
0.9 |
0.8 |
2.1 |
0.9 |
1.6 |
1.0 |
1.4 |
1.2 |
|
B4 |
hair consultant gives courses for new hair professionals |
1.1 |
0.8 |
1.5 |
1.3 |
0.9 |
1.5 |
1.2 |
1.1 |
1.3 |
0.7 |
1.4 |
|
D4 |
weekly meetings on computer to SEE and DISCUSS progress |
1.1 |
1.2 |
1.1 |
0.6 |
0.8 |
2.1 |
1.1 |
1.0 |
1.1 |
1.3 |
1.1 |
|
A4 |
works with people who are not able solve their hair problem |
1.1 |
0.9 |
1.3 |
-0.1 |
1.2 |
1.8 |
0.9 |
1.5 |
1.2 |
0.9 |
1.1 |
|
C1 |
thorough discussion after examination |
1.1 |
0.5 |
1.6 |
0.1 |
0.8 |
2.2 |
1.1 |
0.9 |
1.0 |
1.1 |
1.1 |
|
B3 |
beauty salons often recommend |
1.1 |
1.1 |
1.0 |
1.6 |
0.9 |
1.1 |
1.0 |
1.2 |
0.6 |
1.3 |
1.1 |
|
B2 |
hair consultant writes for social media |
1.0 |
1.0 |
1.2 |
0.7 |
0.9 |
1.5 |
1.2 |
0.9 |
0.9 |
0.8 |
1.4 |
|
B1 |
hair consultant is known by friends |
1.0 |
1.0 |
1.1 |
0.7 |
1.0 |
1.5 |
1.2 |
0.8 |
0.6 |
0.9 |
1.4 |
|
C3 |
present products and/or treatments for the client |
1.0 |
1.1 |
0.9 |
-0.4 |
1.1 |
1.7 |
1.0 |
1.1 |
1.2 |
1.1 |
0.8 |
|
C4 |
present products for the clients |
1.0 |
1.0 |
0.9 |
0.3 |
1.2 |
1.0 |
1.0 |
1.0 |
1.1 |
0.7 |
1.2 |
|
D2 |
client has project and monthly visits |
0.9 |
0.9 |
0.9 |
0.6 |
0.5 |
1.7 |
0.7 |
1.2 |
0.5 |
0.9 |
1.2 |
|
D1 |
client has long term relationship – personal project |
0.8 |
0.8 |
1.0 |
0.1 |
0.6 |
1.6 |
0.7 |
1.0 |
0.8 |
0.8 |
0.9 |
|
A3 |
gives real professional advice |
0.6 |
0.6 |
0.6 |
-0.1 |
0.4 |
1.1 |
0.4 |
0.9 |
0.4 |
0.6 |
0.6 |
|
A1 |
often works with hair which is falling out |
0.4 |
0.3 |
0.6 |
-0.1 |
0.4 |
0.6 |
0.1 |
1.0 |
0.3 |
0.5 |
0.5 |
|
A2 |
works with overly oily hair |
0.3 |
0.4 |
0.1 |
0.3 |
0.2 |
0.4 |
-0.1 |
1.0 |
0.1 |
0.6 |
0.0 |
Table 5 suggests some two simple rules of thumb:
Rule 1 – To engage (although not necessarily to persuade) talk about the process, painting a word-picture of what the client gets as an individual
present alternative best 2 or 3 solutions
client gets reduced salon prices as part of treatment
hair consultant gives courses for new hair professionals
Rule 2 – To not engage, be general, and talk about the problem being solved
gives real professional advice
often works with hair which is falling out
works with overly oily hair
Discussion
The results of this study give a sense of the complexities of daily life. Rather than attempting to introduce a new ‘theory’ of consumer behavior (top down thinking) using a mundane issue such as choosing a hair beauty consultant to confirm or falsify the tenets of such a ‘theory,’ Mind Genomics moves in an orthogonal direction, to ‘map’ the mind. There is no theory, for which the topic of beauty consultant can affirm or falsify. Rather, there is the important effort to be a ‘cartographer’ of the mind, to understand the nature of what confronts people in the every-day, and then construct a science of this ‘ordinariness.’ As these data suggest, the ‘ordinary’ is quite far from simple. There are different mind-sets to be uncovered, different messages which engage versus which are skipped over, and so forth. Indeed, the every-day is far from mundane, but rather presents an entirely new world for science to explore, a world where the discipline of science can fruitfully inform the daily rhythm of life.
Three directions using these results
Our efforts to understand the mind of the consumer when choosing a hair beauty consultant move us in three different directions.
- The decision criteria of everyday. The study revealed two major segments with diverse interests. One is interested in the topic, in the expertise, and probably in the facts. The other is interested in a personal relation. We might move beyond the specifics of hair care consulting, and ask whether this type of division, expertise-respecting vs relationship-seeking, characterize other types of subjects, beyond hair care. Could the experiment with Mind Genomics have uncovered a general division of the mind? And, following the proposition that there are these two main mind-sets, does a person ALWAYS fall into one mind-set or the other, or is the membership labile, a function of the topic, and who the person IS at the moment of the study.
- Applying science for practical benefit. In many disciplines, the mere thought that the data could be used for practical decision-making means that the data are not appropriate for science. Mind Genomics in general, and the results from this study in particular, enable the user to conduct business and daily life in a more efficient manner. Knowing what specific messages to give to a person based upon the person’s mind-set, AND having a way to assign a person to a mind-set, are extremely important for today’s world, for commerce. Increasingly, people are feeling that they don’t want commercial organizations to ‘track their behavior,’ because they feel that such tracking violates the ingredient. Indeed, recent developments in privacy have led to the adoption of a major privacy initiative [27], designed to avoid gathering and using too much data about a person. Fortunately, the only information one needs of a private nature comes from the momentary interaction of a person (identity masked) and the attitudinal questions from the PVI. That data need not even be stored, but simply used at the instant of transaction in order to give a sense of the mind of the prospect to a company
- Creating a data warehouse for knowledge of beauty. The metaphor of Mind Genomics is that for each aspect of experience there are different ways to respond to that aspects, different features about the aspect, and of course, different messages. The objective of a Mind Genomics study is to ‘map’ these ways, to reveal the science of every-day. In recent years author Moskowitz and colleagues have suggested that another opportunity may be to create large-scale databases, of many studies within the same topic, here beauty. The studies are straightforward to design and to execute. The world of beauty itself may comprise dozens of different topics, each of which generates its own Mind Genomics study, and in turn each Mind Genomics study uncovers the mind-sets, and is finished off by the PVI, personal viewpoint identifier, for that topic. What might be the arc of knowledge if instead of one PVI completed by a person, 20 or more PVI’s were to be completed, for the wide arc of beauty. Each person would, in fact, generate a vector of some 20 different mind-sets to which a person might belong, based on the patterns of the individual’s separate PVI’s. Such a vector of PVI’s could form the basis of a deep understanding of the mind of people in a life-relevant area (beauty), with the membership patterns of hundreds of thousands of individuals established through a set of PVI’s correlated with biological factors, social factors, and one’s own intellectual/personality factors. Such is the promise of a Mind Genomics, the science of the everyday, with a simple demonstration here in this paper for a simple, but relevant topic to daily life, one’s hair.
Acknowledgment
Attila Gere thanks the support of the Premium Postdoctoral Researcher Program of the Hungarian Academy of Sciences.
References
- Chrisler JC (2007) Body image issues of women over 50. In Women Over 50: 6–25. Springer, Boston, MA.
- Chrisler JC and Ghiz L (1993) Body image issues of older women. Women & Therapy 14: 67–75.
- Gillen MM and Dunaev J (2017) Body appreciation, interest in cosmetic enhancements, and need for uniqueness among US college students. Body image 22: 136–143.
- Kasardo, Ashley E, Maureen C. McHugh (2015) “From fat shaming to size acceptance: Challenging the medical management of fat women.” The wrong prescription for women: How medicine and media create a “need” for treatments, drugs, and surgery, 179–201.
- Rhode DL ( 2009) The Injustice of Appearance. Stanford Law Review 1033–1101.
- Saltzberg E, Chrisler J, Disch E (2006) Beauty is the beast: Psychological effects of the pursuit of the perfect female body. Moral Issues in Global Perspective: Volume 2: Human Diversity and Equality 2: 142.
- Trüeb RM, Tobin D. eds. (2010) Aging hair. Springer Science & Business Media.
- Gillespie CH (2013) Down to the roots: A qualitative analysis of the psychological impacts of messages black women receive regarding their hair. Southern Illinois University at Carbondale.
- Linnan LA, Ferguson YO (2007) Beauty salons: a promising health promotion setting for reaching and promoting health among African American women. Health Education & Behavior 34: 517–530.
- Xu G, Feiner S (2007) Meinü Jingji/ China’s beauty economy: Buying looks, shifting value, and changing place. Feminist Economics 13: 307–323.
- Yan Y, Bissell K (2014) The globalization of beauty: How is ideal beauty influenced by globally published fashion and beauty magazines?. Journal of Intercultural Communication Research 43: 194–214.
- Yang J (2011) Nennu and shunu: Gender, body politics, and the beauty economy in China. Signs: Journal of Women in Culture and Society 36: 333–357.
- Moskowitz HR, Gofman A, Itty B, Katz R, Manchaiah M et al (2001) Rapid, inexpensive, actionable concept generation and optimization: the use and promise of self-authoring conjoint analysis for the food service industry. Food Service Technology 1: 149–167.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & Behavior 107: 606–613.
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of sensory studies 21: 266–307.
- Moskowitz HR, Gofman A, (2007) Selling blue elephants: How to make great products that people want before they even know they want them. Pearson Education.
- Luce RD, Tukey JW (1964) Simultaneous conjoint measurement: A new type of fundamental measurement. Journal of mathematical psychology 1: 1–27.
- Green PE, Rao VR (1971) Conjoint measurement for quantifying judgmental data. Journal of marketing research 8: 355–363.
- Green PE, Srinivasan V (1990) Conjoint analysis in marketing: new developments with implications for research and practice. The journal of marketing 54: 3–19.
- Box GE, Hunter WG, Hunter JS (1978) Statistics for experimenters, New York, John Wiley
- Dubes R, Jain AK (1980) Clustering methodologies in exploratory data analysis. Advances in Computers 19: 113–238.
- Zemel R, Gere A, Papajorgji P, Zemel G, Moskowitz H (2018) Uncovering consumer mindsets regarding raw beverages. In Food and Nutrition Sciences 9: 259–267.
- Wells WD ed. (2011) Life Style and Psychographics, Chapter 13: Life Style and Psychographics: Definitions, Uses, and Problems. Marketing Classics Press.
- Kahneman D, Egan P (2011) Thinking, fast and slow. New York: Farrar, Straus and Giroux.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127–145.
- Moskowitz H, Gofman A, I novation Inc (2003) System and method for content optimization. U.S. Patent 6: 215,662.
- GDPR (General Data Protection Regulation), 2018, Wikipedia: https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
- Moskowitz HR (2014) 14 Mind genomics→ and texture: the experimental science of everyday life. In” Food Texture Design and Optimization (Dar, Y.L. and Light, J.M. eds.,) John Wiley.
- Moskowitz HR, Porretta, Sebastiano, Silcher, Matthias (2005) Concept Research in Food Product Design and Development. Hoboken, New Jersey: Wiley-Blackwell Publishing. 612pp
- Van Kleef E, Van Trijp HC, Luning P (2005) Consumer research in the early stages of new product development: a critical review of methods and techniques. Food quality and preference 16: 181–201.